What is it?
AtMan is an attempt at helping users know the source of the answer/completion given by LLMs (Large Language Models). Unlike other existing methods, AtMan is memory efficient and is also multimodal (i.e it works on both images and text).

Existing methods to explain the outputs of neural networks are generally classified into one of the 2 given types:
-
Gradient based methods:
- Require a backward pass, which takes up almost double the memory as that of a forward pass.
- Generally also requires knowledge about the model’s architecture (which layer’s gradients/activations do we take etc)
-
Perturbation based methods:
- Require less memory, but involve making lots of “blintd” perturbations to the input and tracking the changes in the output.
- The neural network can be treated as a black box.
- Generally less accurate when compared to the former
AtMan is an attempt to get the best of both worlds, instead of making blind perturbations on the input space, we make deliberate perturbations on the intermediate representations within the layers which alter the flow of information across the sequence dimension (i.e the attention scores). This was particularly inspired by the idea of “Attention Heads as Information Movement” found here.
Why do we need it?
LLM based systems like that of ChatGPT are good at helping you rephrase your emails and writing blog posts. But it is basically useless for high-value work unless we have a way to know when to trust it and when not to.
For example, let’s assume you have an LLM based document Question-Answering engine. Given that it’s a good LLM, your user will surely get the answer. But would a lawyer feel confident enough to blindly trust the LLM’s answer for an argument on behalf of his client?
What if the lawyer not only wants an answer, but also wants to find the part of the document which led to it?
This is where AtMan comes into play. It would let the lawyer know that this is the part of the document that led to the answer.
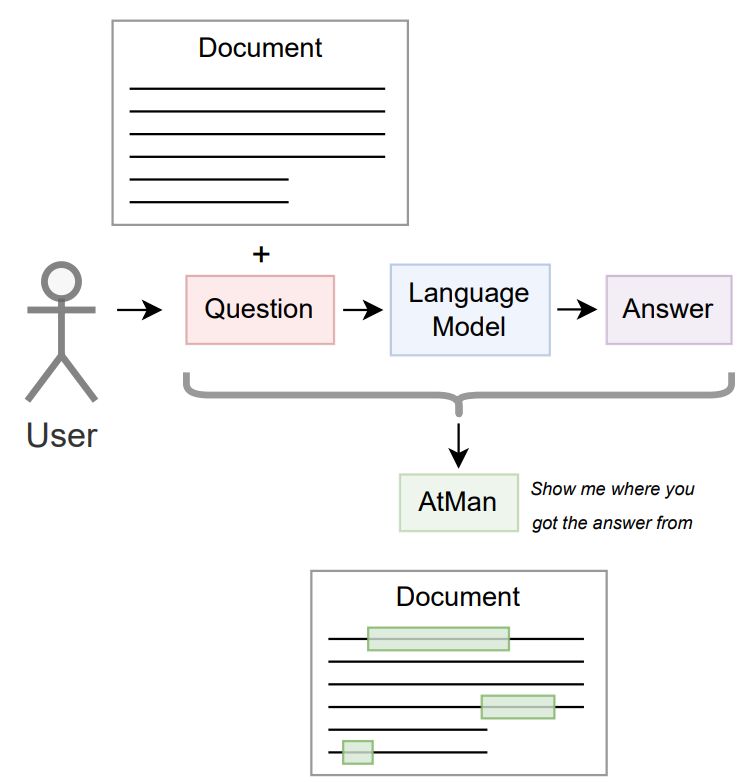
The examples shown below demonstrates how AtMan helps validate the answer given by an LLM:
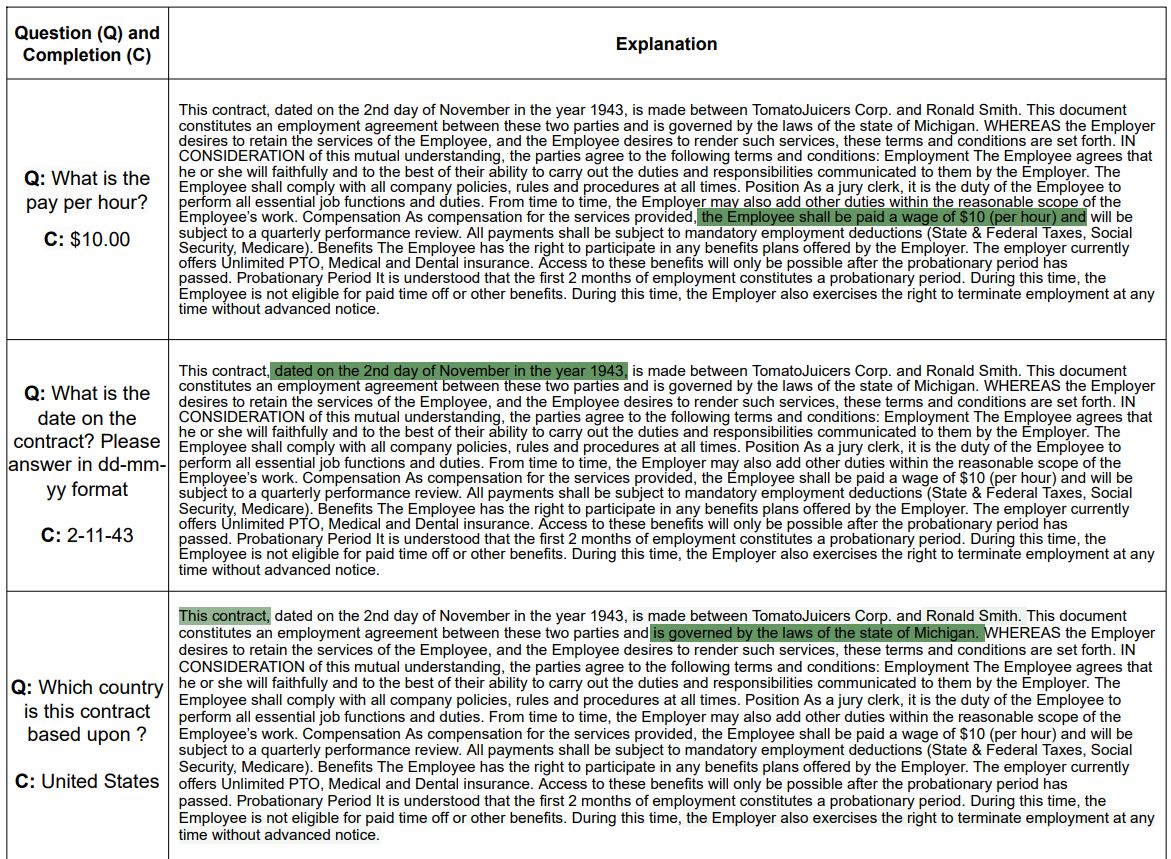
Another use-case for AtMan is to detect when the LLM is really looking at the document v/s when it’s hallucinating world knowledge. This way, we will know when your LLM is not blurting out garbage which looks like a valid answer. Notice how on the example shown below, nothing is highlighted on the text. From this, the user can infer that the answer given by the model has nothing to do with the document.

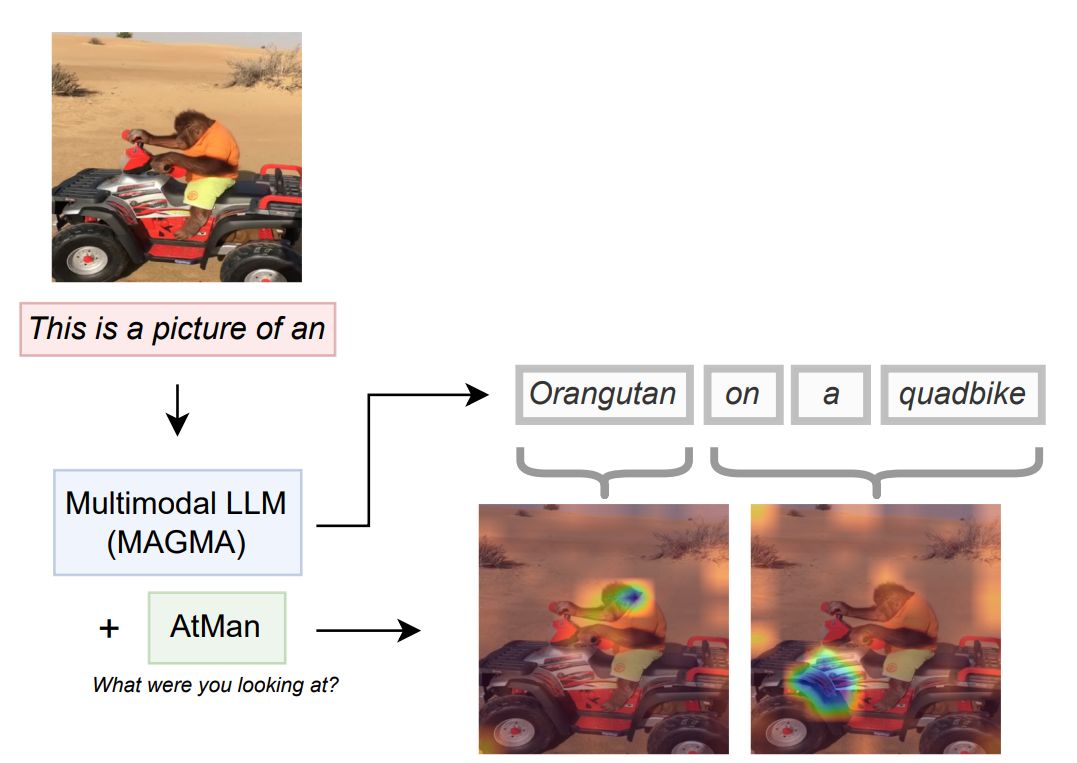
AtMan also works surprisingly well for localization of objects in an image as seen below.
How does it work?
The core idea is quite simple: we erase a small part of the input at a time and look at the change in the output. If the output changes a lot, then that erased part is assumed to be important. For text, we can do this by erasing one single token at a time. For images, we do the same by erasing a single image patch at a time.
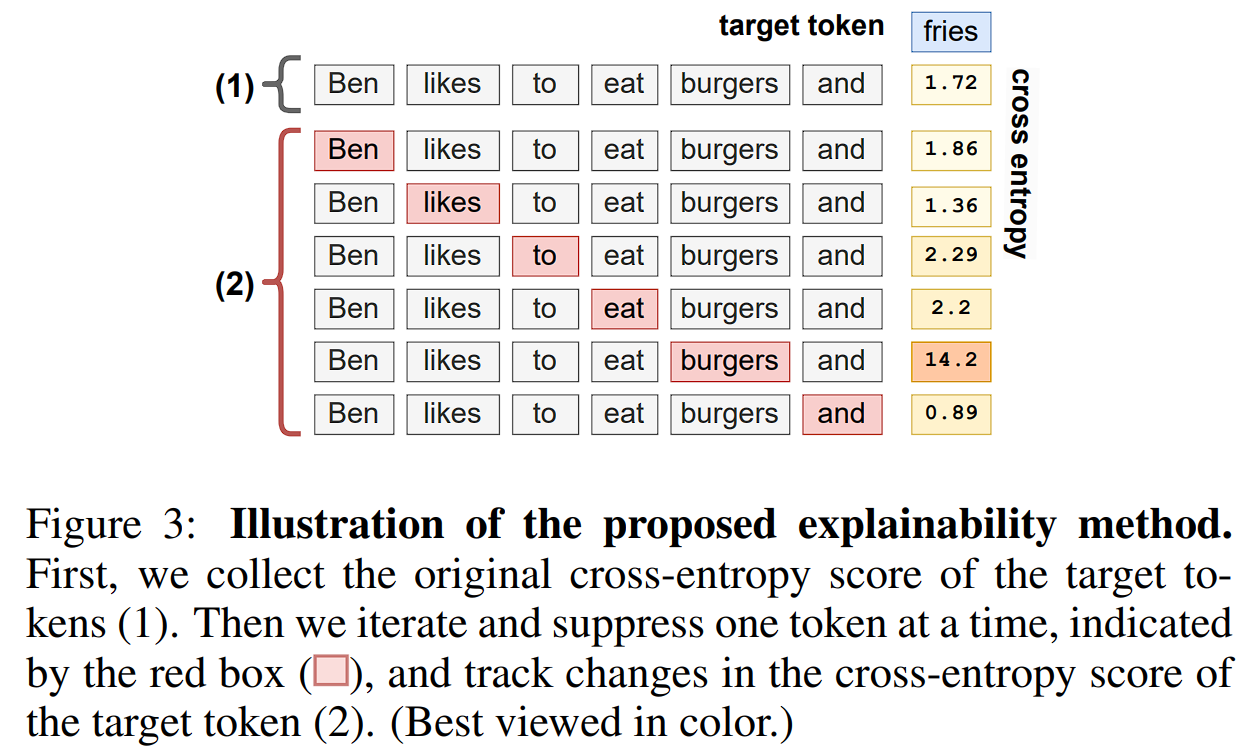
Unfortunately, the idea discussed above does have a small flaw which we realized and managed to fix later for images. It has been discussed in section 3.3 in the paper.
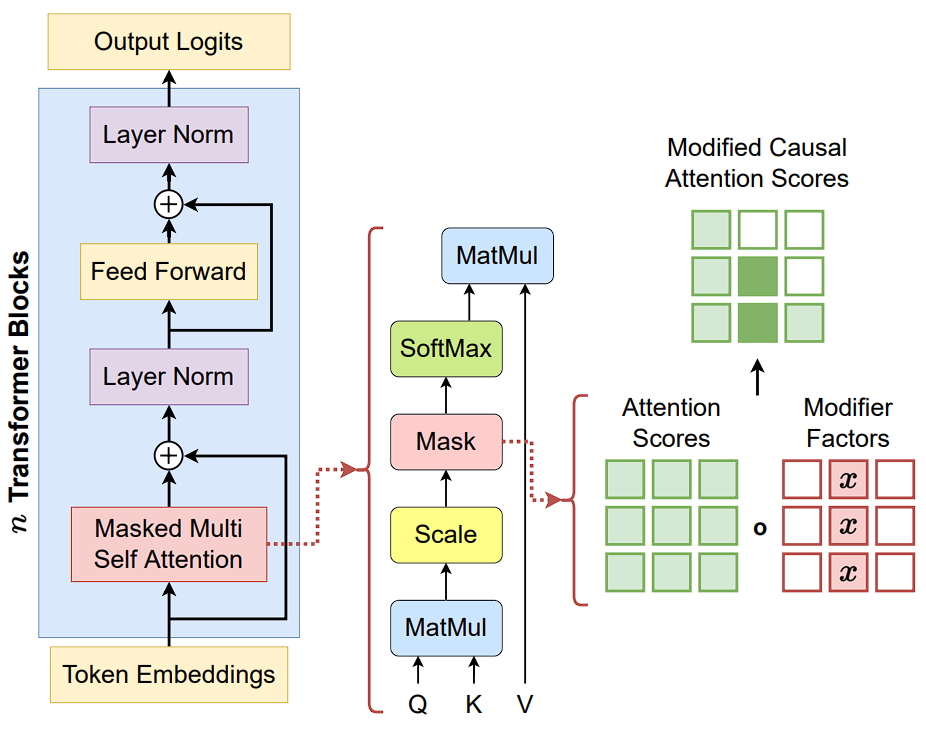
The neat thing about AtMan is that it requires only forward passes, hence it’s super easy to deploy into pre-existing LLM inference pipelines with only minor modifications to the attention module.
So how do we Erase tokens?
We do this by manipulating the attention scores in each transformer layer by scaling down the values corresponding to the input token(s) to be suppressed. In the example shown below, x would be 0.1 in order to suppress the input token at index 1.
If you have read this far, I highly encourage you to read the paper!