The videos from the EPIC dataset were not all clean and tidy, some of them had random black frames, and some even had random red lines/patches through the frame. These factors were highly unfavourable when it came to training a good deep learning model. This problem was solved in this notebook.
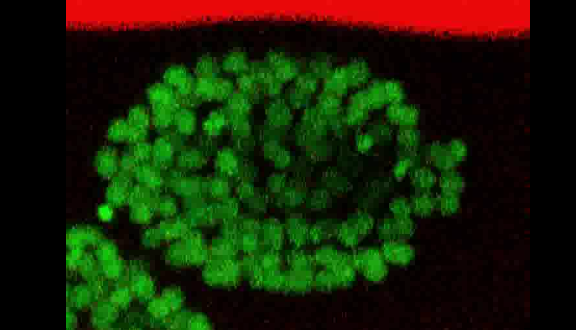
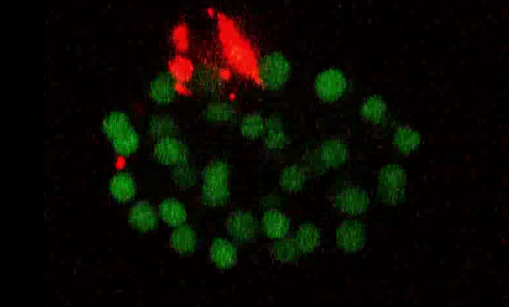
And as it turns out, these images were also acompanied with corrupt annotations, where the population went down to zero all of a sudden, even through the associated frames had well populated embryos. I called them the “cliffs”.
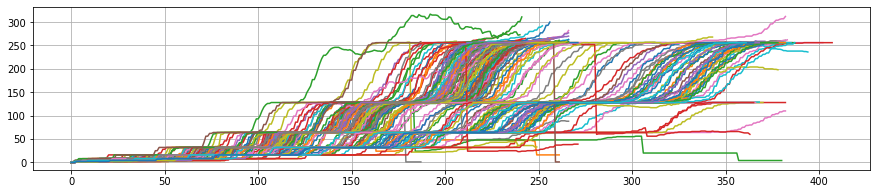
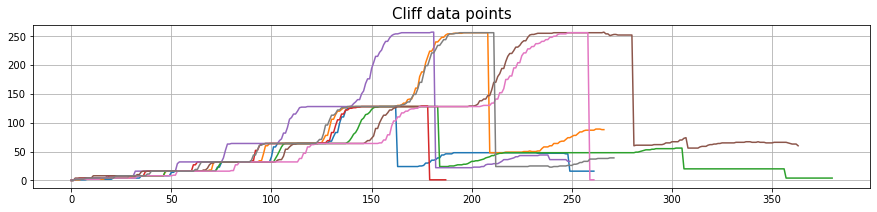
As it was seen above, some of the data points had cases where the population went down almost vertically all of a sudden. Upon further inspection, it was found that the frames associated with these drops were well populated with cells and definitely not as depicted by these “cliff curves”. So the next step was to remove them.
Now the only problem that remained was to remove the corrupt random frames with the patches. For this problem, I went on with ujjwal‘s aproach, which involved dropping the frames with the highest loss after a few epochs of training and the re-train on the “clean” frames.

The plot above shows the loss of each frame in the training set, with the red lines highlighting the top 10% frames with the highest loss after training.
Expecting a much lower loss next week.