Before you move on to trying to understand how a transformer works, it’ll be a good warmup to understand some of the key mechanisms that are present within them.
This is the stuff you need to know about:
- Tokenization
- Positional Encodings
- Vector similarity in N-D spaces
- Self attention
- Short residual skip connections
- Layer Normalization
- Multi head attention
Tokenization
Tokenization is a way of separating a piece of information into smaller units called tokens (of course theyre called tokens).
Tokenization can take different forms depending on the task:
- In NLP, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into 3 types – word, character, and subword (n-gram characters) tokenization.
For example, when we apply “word tokenization” to"hello how are you", it becomes:
[
'hello',
'how',
'are',
'you'
]
Here the order of the words is not relevant.
- For vision based tasks, tokenization takes a very different form. One of the ways is to simply chunk the image into smaller patches, flatten them into vectors, concat/add positional embeddings and voilá. The Vision Transformer (ViT) does exactly this - with an additional transformation after the flattening to reduce the dimension of the tokens.
This is how its done:
- Chop down the image into 16x16 patches
- Flatten the patches
- Produce lower dimensional linear embeddings from flattened patches.
- “Add in/concat” positional embeddings.
This section in another post elaborates on how tokenization is acheieved using image patches.
Positional embeddings
When preparing a token, it is always good to also include information on “where it is” and not just “what it is”. This is what a positional embedding is. Generally its concatenated/added into the image/text embedding before feeding it into the transformer encdoer.
Vector similarity in N-D spaces
One way to find the similarity between 2 vectors is to determine their scaled dot product, namely the cosine of the angle. It is a stable way of detecting how “equal” two vectors are in relation to both direction and distance. Its values vary from -1 to 1.
import math
def similarity(v1,v2):
"""
This is just a dummy example, please dont use it in practice.
compute cosine similarity of v1 to v2: (v1 dot v2)/(||v1||*||v2||)
Also see: https://deepai.org/machine-learning-glossary-and-terms/cosine-similarity
"""
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y = v2[i]
sumxx += x*x
sumyy += y*y
sumxy += x*y
return sumxy/math.sqrt(sumxx*sumyy)
x = [-41,-62,-600]
y = [2,3,4]
print(similarity(x,y))
Self attention
In a nutshell, it is a way to differentiably “select/focus on” certain parts of the embedding more than the others. I’ve written a post where I’ve tried to explain how it works from scratch.
Short residual skip connections
You might know this already but they basically act as “information bridges” which helps the gradients flow back from deep into the model into the earlier layers very easily. Stuff that makes up the “Res” in “ResNets”.
Layer Normalization
Let’s first try to see whats batch normalization, this will help us understand layer normalization later on.
Batch normalization is not needed here, but you should know how it works
Mathematically, BN layer transforms each input in the current mini-batch by:
- Subtracting the input mean in the current mini-batch
- Dividing it by the standard deviation.
But each layer doesn’t need to expect inputs with zero mean and unit variance, but instead, probably the model might perform better with some other mean and variance. Hence the BN layer also introduces two learnable parameters γ and β (gamma and beta).
The important thing to note here is that this normalization works along the batch dim.
ok so how is layer normalization different from batch normalization ?
The only difference is that layer normalization individually (along the feature axes) normalizes each feature to have zero mean and unit variance.
Multi-head attention
Multi-head attention is just multiple attention blocks in one single layer whose outputs are concatenated later after the forward passes. The main advantage is that it allows us to attend to different parts of the sequence differently on each “head”.
In caveman words: multi head attention is just a “bunch” of attention mechanisms in a single forward pass
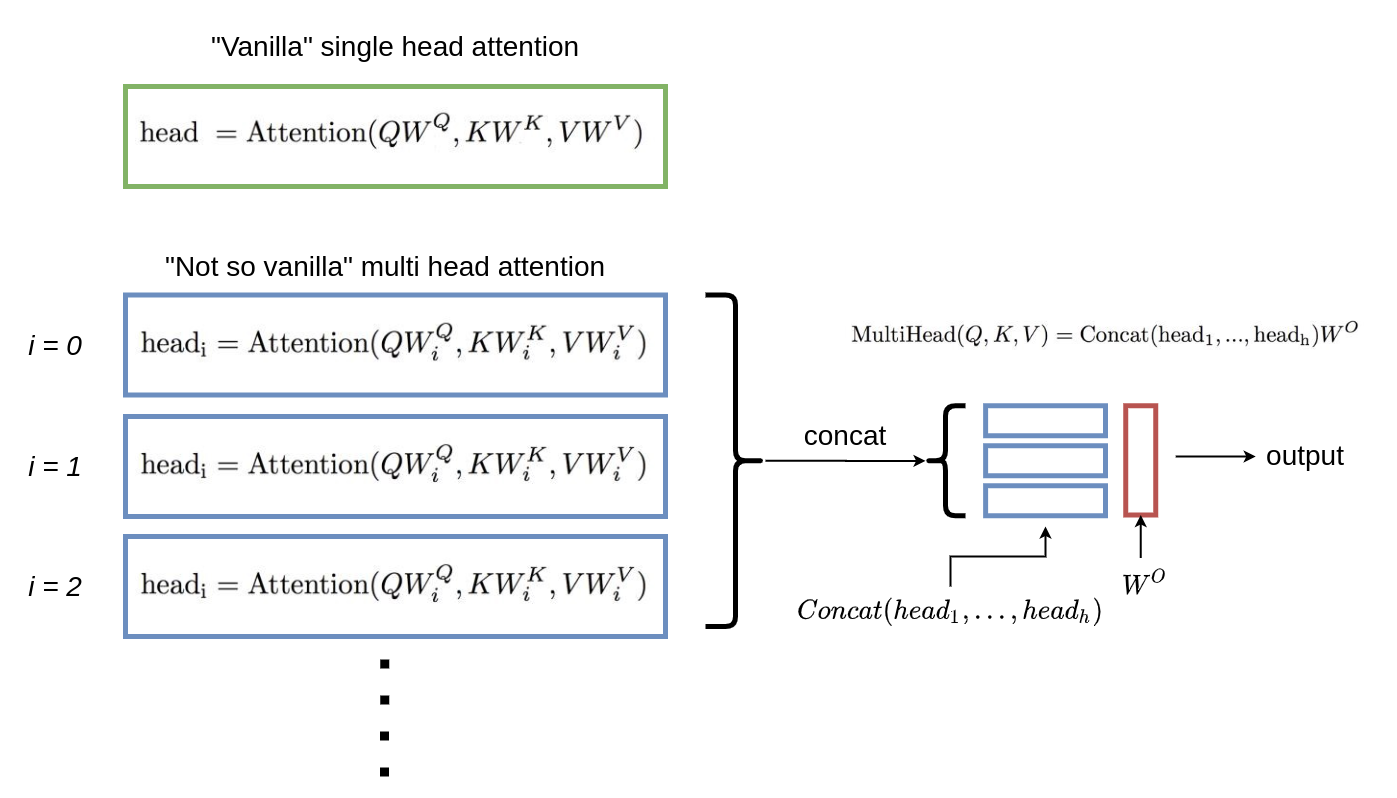
Further reading:
-
The vision transformer: https://theaisummer.com/vision-transformer/
-
An image is worth 16x16 words, explained: https://www.youtube.com/watch?v=TrdevFK_am4